Throughout my time at Twilio, I’ve often wondered why some software infrastructure companies become massive businesses while others falter. What is it about the nature of certain products and the markets they target that makes it possible to build large infrastructure platforms? This post is an attempt to structure what I’ve learned about this question and was prompted by a series of conversations I’ve had recently with early stage API infrastructure companies about product and go-to-market strategy.
In my opinion, your startup’s target market must have the following characteristics for it to turn into a massive business:
- The risk to the customer’s business of being locked into your infrastructure must not be prohibitive.
- The opportunity cost of building the same infrastructure in-house must be high enough to consider buying it from a third-party.
- There need to be enough customers that meet criteria (1) & (2) willing to pay what’s needed to support a market for it.
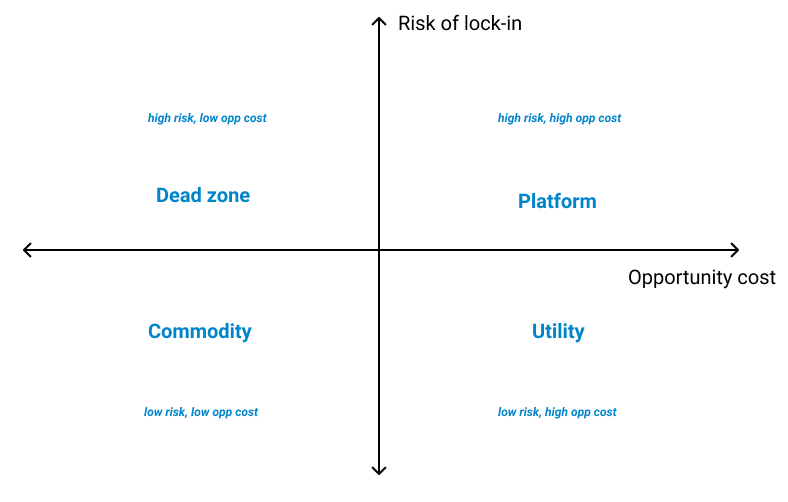
Startups that build APIs for problems that have a high opportunity cost to solving in-house relative to the risk of depending on a vendor have the highest chances of breaking out to become massive companies. Low opportunity costs mean your customers can easily build the same infrastructure in-house, and a low risk of lock-in means they can always switch you out. The sweet spot lies in providing infrastructure that’s hard to migrate from, resulting in a high risk of lock-in, but provides substantially more value than the opportunity cost of building in-house.
To begin exploring this question in detail though, you need to start with the company that started it all — Amazon Web Services.
1. Land and expand
The advantages of building on a cloud platform are clear as day today. For startups and increasingly for enterprises that need to move to digital business models, using APIs instead of setting up servers turns upfront capital costs into ongoing operational costs, provides instant scaling and eliminates the overhead of maintaining data centers. Even the most sophisticated companies will think twice before building their own data centers today.
If you trace the trajectory of products launched by AWS since they announced SQS in 2004, a pattern emerges. Over the years, AWS has moved up the application stack with new releases to provide infrastructure that is tailored to solving increasingly specific software development problems. These APIs are more opinionated i.e. they force you to build software in a certain way, and tightly integrated with AWS infrastructure, but also a lot easier to use. Jerry Hargove has drawn up this fantastic timeline of every single AWS launch since 2004 and grouped them into categories.
Today, developers can build applications on AWS with APIs providing different levels of abstraction. If you’re looking to build a video streaming application, you can directly use AWS Media Services without worrying about the underlying transcoding, storage and bandwidth infrastructure. But, if you’re looking for more control over your application, perhaps you need to run a custom transcoder optimized for your use case, you can build a video streaming stack using EC2, S3 and CloudFront. I arranged the categories Jerry uses by the general level of abstraction provided by it’s members to illustrate my point. I didn’t consider newer bets like AWS Ground Station or AWS RoboMaker, or horizontal utilities like Developer Tools or Cost Management.
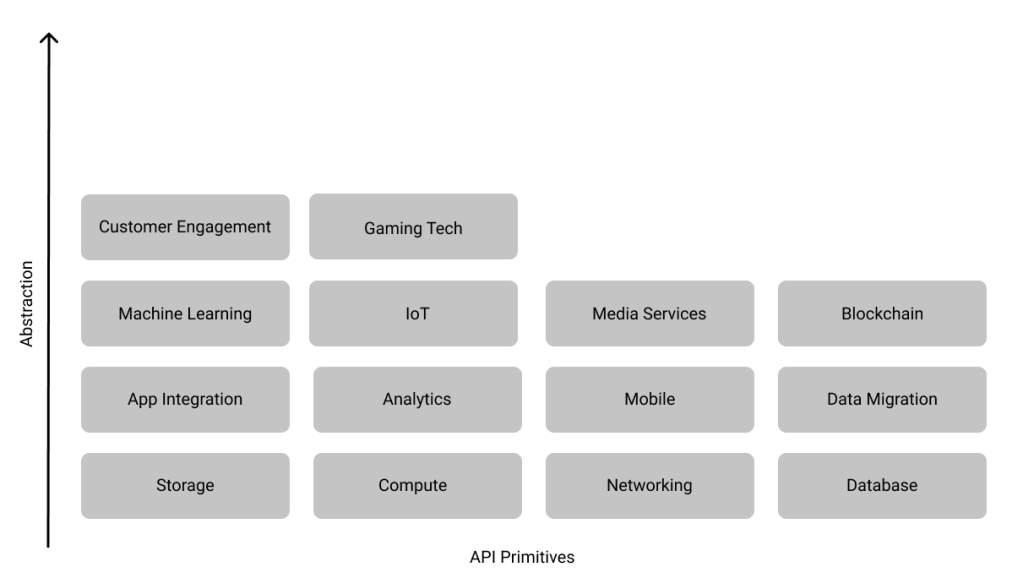
AWS APIs that provide more abstraction generally charge higher prices because they can significantly simplify application development and decrease release times. They probably also have higher gross margins for AWS.
This general pattern — starting with lower level APIs, raw compute, storage and networking in AWS’s case, and moving up the stack over time isn’t unique to AWS. Almost every single successful API company founded since the advent of public cloud platforms has followed this strategy.
Twilio’s first product was an API for making and receiving phone calls. Their second product was an SMS API. Since then, they’ve expanded to provide dedicated APIs for two-factor authentication, video conferencing, VoIP, WhatsApp and in-app chat. Recently, they moved even further up the stack with Flex, a programmable contact center that bundles these APIs together under a customizable UI framework.
Stripe’s first product was an API for accepting payments. When they started seeing a lot of traction in e-commerce, they launched a UI framework to make building checkout experiences easier. When they saw a lot of traction from marketplace companies, they built Connect to simplify on-boarding and verifying sellers and routing payments. Since then, they’ve launched APIs for subscription and invoicing, fraud detection and card issuance.
Segment started off providing a unified API for ingesting customer and usage data from multiple sources and loading it into different business analytics tools. Today, they’ve built products that aggregate this data to provide a 360-degree view of each customer, allowing businesses to enrich existing customer data, build audiences in real time and create personalized experiences.
DataDog’s first products were monitoring APIs for virtual machines and cloud instances. Since then, they’ve expanded to other cloud backend configurations like containers and serverless, while also moving up the stack to provide logging and monitoring solutions for middleware and applications.
This ability to land and expand is what separates the wildly successful infrastructure companies from those that fail to take off. This expansion happens horizontally, as more teams come to rely on their API and as they provide APIs at similar levels of abstraction for adjacent use cases, and vertically, as their customers start adopting higher level APIs to solve more specific problems. The beauty of this model, if you can get it right, is that all you need to do to identify new product opportunities is closely observe what applications your customers are building. A large enough number of customers building the same types of applications usually represents an opportunity to provide a higher-level API. This expansion also makes their infrastructure harder to replace, resulting in stellar revenue growth rates and net dollar retention numbers.
I think there’s a more fundamental question you need to ask then to answer the original question — why do some API infrastructure companies land and expand successfully? It starts with understanding the alternatives available to their prospective customers.
Every SaaS product’s toughest competitor is the customer not buying! The hardest customers to sell to think they don’t even have the problem your product solves. What’s every infrastructure product’s most formidable competitor then? Alongside not buying, it’s the customer deciding they can build the same capabilities in-house instead of integrating with a third party.
A customer buys infrastructure if the risk of being locked-in to a vendor is lower than the opportunity cost of building it in-house. API infrastructure companies that demonstrate enough value to overcome the perceived risk of lock-in find it easier to land within their customer’s application stack, expand and become massive companies.
2. Vendor lock-in dynamics
The more reliant a company becomes on a third party, the harder they find it to replace them. This risk isn’t unique to software infrastructure. But a thorough understanding of the risk of vendor lock-in from the customer’s perspective is the most important input to the strategy of any API infrastructure company. This risk is higher if the third party isn’t completely modular i.e. swapping them out is expensive, time-consuming and can have second or third order effects that are hard to predict.
Apple’s decision to move away from Intel is a classic example of vendor lock-in gone wrong. They’re replacing Intel’s chips with their own A-series chips (the same chips that power iOS devices) in all new Macs released in 2021 and beyond. This is going to be a complex transition for Apple because the A-series chips are based on ARM while Intel’s chips are based on the x86 architecture. Apple is bringing chip design in-house because Intel has fallen far behind TSMC in processor node size. TSMC started working on 5 nm chip this year while Intel is still stuck producing 14 nm chips. Intel was also increasingly the bottleneck for Mac innovation — Retina displays took longer to arrive on the Mac than on the iPhone because Intel’s production of 14 nm chips was delayed. Replacing Intel gives Apple full control over the entire Mac stack, allowing them to optimize performance and build features on their own timeline. The risk of depending on Intel ultimately wasn’t worth the benefits.
I’ve most frequently seen four types of vendor lock-in with software infrastructure companies.
- Tightly coupled architectures
- Economies of scale
- Developer experience
- Network effects
The lock-in can be quite formidable if more than one type is in play.
Tightly coupled architectures
If using a vendor requires you to explicitly design your software within the constraints of their API, your architecture can get tightly coupled to theirs. The degree to which this happens is hard to assess when you first make that decision because the immediate benefits — speed and implementation costs, are usually obvious, and vendors put a lot of work into making their APIs extremely easy to adopt. It’s only as you scale does the extent to which you’re coupled starts becoming obvious.
Implementing on AWS is the most obvious example here of making a decision that leads to tight coupling. It can be extremely hard to move off AWS, especially if you’ve come to rely on their higher-level APIs! Google’s decision to open-source Kubernetes was specifically targeted at this dynamic. Containers make it significantly easier to run software on multiple cloud providers.
Economies of scale
This dynamic comes into play typically when the service provided by the API infrastructure company has a hard cost to deliver. Take Twilio, Stripe and Cloudflare for example. Each company has an underlying cost to deliver their services, in addition to the cost of their own software and overhead. With Twilio, it’s the cost of text messages and voice minutes, Stripe it’s payment processing fees to Visa and MasterCard and with Cloudflare it’s bandwidth. As these platforms scale, they’re able to negotiate better terms with their suppliers, which they can then pass on to their customers. For a customer, going directly to their suppliers will result in higher prices because most companies can’t match the scale of these platforms.
Developer experience
Developers are increasingly decision makers, or at least important influencers in most software purchase decisions today. This is especially the case with software infrastructure companies. Building APIs that developers love and rely on can also be a significant source of lock-in. And it’s not just about great documentation, building a great community or ease of use. It’s also about how embedded your product can get in the development workflow. This is why so many API infrastructure companies have command line interfaces and support for tools used for continuous integration and continuous delivery pipelines.
Network effects
Network effects are less common because most API infrastructure companies operate multi-tenant systems designed to separate customer data as much as possible. They also don’t typically facilitate transactions between customers on the platform. But network effects can manifest on the supplier side and become a significant source of lock-in. Plaid is a great example of this. For each new financial institution they add to their platform, the value of choosing Plaid over a competitor increases.
3. Risks from vendor lock-in
If these lock-in dynamics create opportunities for infrastructure companies, they create risks for their customers.
- Execution risk
- Scaling risk
- Cost structure risk
The greater the perceived risks, the higher the value delivered by your infrastructure needs to be.
Execution risk
What happened with Apple and Intel is in a sense a great example of execution risk. As Intel struggled to keep up with TSMC, Apple realized they stood to gain more by bringing chip design in-house and outsourcing manufacturing to TSMC than relying on Intel for both design and manufacturing. Not only do they now get Intel’s margin on the chips, they don’t have to be constrained by Intel when launching new features, ensuring incidents like the delay on shipping Retina screens in 2015 would never take place.
When a company buys infrastructure instead of building it in-house, it’s making a bet on the vendor’s vision and ability to execute on their roadmap. The last thing they want is to depend on a vendor that can’t keep up with their roadmap. This is less of an issue for established infrastructure companies, but for startups allaying these concerns upfront is critical.
Scaling risk
The same calculus applies to the vendor’s ability to scale. Companies buying infrastructure want to know whether it can handle their existing transaction volume, manage volatility in volumes and add capacity to support increases in volume over time. Established infrastructure companies like Twilio, Stripe and DataDog got around this problem in part by first selling to startups. As WhatsApp, Uber, Lyft and AirBnB started growing rapidly, they scaled in tandem to build the capacity required to support larger enterprises later on.
Not all API infrastructure companies need to sell to startups or individual developers at the beginning. In fact, most companies are unlikely to have an addressable market with a long tail of small customers. If you’re selling to enterprises from day one, structuring the engagement like a professional services or custom software development contract can be effective at addressing this concern, while also giving you a deeper understanding of their requirements.
Cost structure risk
When a company decides to use Stripe instead of becoming a payment facilitator themselves, they’re giving up the ability to negotiate favorable payment processing fees with the card networks. This is a major selling point for long tail developers and small and medium businesses. It’s also a compelling reason to use Stripe for larger businesses that don’t have the appetite to integrate directly with banks and card networks. But for businesses processing hundreds of millions of dollars every year, each cent they pay Stripe on top of the fees charged by Visa and MasterCard starts to add up. Bringing payment processing in-house starts to look very attractive. Startups like Finix have emerged to allow companies to do just that without building a payments processing stack from scratch.
4. Opportunity costs
The opportunity cost of building infrastructure in-house is essentially the cost of the engineering team needed to build, operate and maintain it not working on something else. The calculus is straightforward — is it a better investment to have expensive engineers build software you could just plug in from a third-party instead of working on features that will differentiate your core product? There’s also an element of execution risk here — once built, can your team add features and scale faster than a third-party whose entire business depends on providing the best infrastructure possible?
The opportunity cost is inversely proportional to how strategically important the infrastructure is to the business model of the company. Taking an extreme example, Netflix would never use a third party video streaming API even though it could significantly lower their engineering costs. The opportunity cost is non-existent here because of how critical owning the end-to-end video streaming infrastructure is to their business. WhatsApp is an example on the other extreme — SMS verification is a core part of their user on-boarding flow. But the opportunity cost of directly connecting to every single carrier in the world is too high! It makes more sense to use Twilio than divert engineering resources from working on the core product. That’s also why WhatsApp, or any other chat app for that matter will never use a third party for their real-time messaging infrastructure.
In my experience, it’s hard for customers to measure opportunity costs systematically and objectively. They can only be considered when the build or buy decision is being made and depend on business priorities, budget constraints, market conditions and with larger companies, internal politics.
5. Clearing the threshold
It follows then that customers only derive value from API infrastructure if the opportunity costs are higher than some minimum threshold and the risk of lock-in is lower than some maximum threshold. Understanding these thresholds for your addressable market is critical to determining if you have product-market fit.
Here are a few questions I’ve found useful when evaluating the target market for an API infrastructure company.
Vendor lock-in
- What scale are your target customers operating at? Typically expressed in usage or API calls.
- Can your platform handle their scale over time?
- How complex is the integration? Focus on how much additional work the customer needs to do to start seeing value from your API. Do they need to build a UI or integrate with Salesforce for example?
- How sensitive is the data they’re sending you? Are you storing it?
- How much is your roadmap and vision aligned with theirs?
- What portion of their service delivery cost is your infrastructure?
Opportunity costs
- How strategically important is this functionality?
- How large an engineering team do they need to build and operate this in-house?
- Is this something their engineers are excited to work on?
- Are there on-going non-engineering costs like regulatory compliance, security overhead and complex contractual relationships?
- Does building require maintaining a large number of third-party integrations?
- Will cost and performance improve meaningfully with constant optimization
Thanks for reading — this post may have gotten a bit wonkier than I intended! Please send your thoughts and feedback to me on Twitter: @pranaveight.
